Deep pagination using search_after and Point in Time (PIT)
Context
-
At
$work, I was tasked to build a feature that required fetching existing data from more than 10,000 documents and then reindexing these documents across a few indices in Elasticsearch. -
However we know that Elasticsearch has a traditional limit of 10,000 hits being fetched in a single query to safeguard the memory and CPU usage.
-
Of course, we can go ahead and increase the limits of the
index.max_result_windowsize to circumvent the issue. But, this again comes at the cost of using more resources (CPU & memory wise). In light of an ever growing index, this might be a quick solution for some cases but not necessarily a good long term solution.
In this blog post, we talk abit more about the solution provided by Elasticsearch - which is using Search After and Point In Time.
Search After and Point In Time (PIT)
- A search request by default executes against the most recent visible data of target indices
- A PIT is a lightweight view into the state of the data when initiated
- If multiple search requests were made and there are refreshes that happened between search_after requests, the results might be inconsistent
- This is due to changes happening between searches are only visible to the more recent point in time.
- Might be preferable for multiple search requests to use the same PIT
- As mentioned- by default ES only allows for up to first 10,000 hits. Subsequent hits need to be used with
PITandsearch_afteras recommended by ES.
Keep Alive
- The keep_alive parameter is passed to a open PIT request and search request.
- It is used to EXTEND the TTL of the corresponding PIT
- e.g
1m(see time units)
- e.g
- It is used to EXTEND the TTL of the corresponding PIT
- It does not need to be long enough to process all data, just needs to be long enough for the next request
- i.e if a request takes 30s and has a keep_alive of 5m, it will extend the current PIT by 5m
- if there are 10 requests, the timer resets and extends the keep alive by 5 minutes.
- It does not accumulate the time for each subsequent request
What is happening underneath the hood with Point In Time and Refresh?
- Normally the background merge process optimizes the index by merging together smaller segments to create new bigger segments.
- Once the smaller segments are no longer needed they are deleted
- But open PITs prevent the old segments from being deleted since they are still in use.
- Which also means that keeping older segments alive uses more disk space and file handlers are needed.
- If a segment contains deleted or updated documents, then the PIT must keep track of whether each document inside was live at time of initial search request
- This means we need to have enough heap space if we have many open PIT on an index that is going through deletes or updates.
What are Segments In ES?
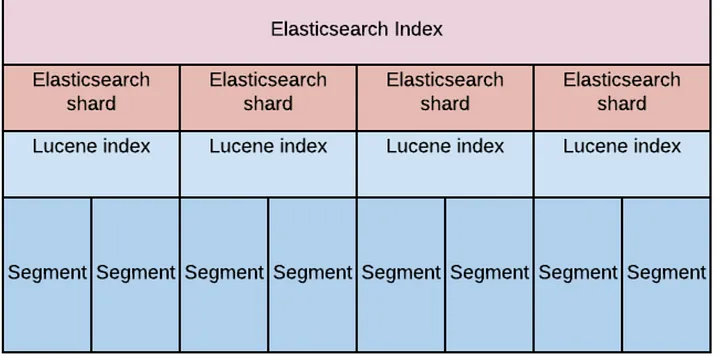
- Elastic Search indexes are actually sharded Apache Lucene indexes.
- Lucene has been optimized for performance and to achieve performance each individual Lucene index is divided into smaller files called segments.
- These segments are immutable, whenever we update a document, it actually gets created in a new segment, the old document is marked for deletion
- Elasticsearch periodically merges segments, which deletes old segments.
- We can force merge segments, but merging does have a CPU and I/O cost.
- Recommended to turn off merging of segments when doing bulk indexing
- Elastic Search also balances the shards periodically.
Index Operation Delay
- When I wrote an integration test for an index operation, I noticed that tests would fail because the information has not be reflected in the index yet
- Putting a 1 or 2-second sleep between indexing and a search request will make it work consistently but that would mean slowing down our tests
- The reason for this is that the shards acknowledge once they have written the document to a “transaction log” (similar to “write ahead log” like most databases), but they are not yet part of the live index.
- We can also make the index available immediately by using refresh
- By default ES sets the
refresh_intervalto one second
- By default ES sets the
If you are using the Elasticsearch python library like I am, we can easily do this by setting parameter refresh=True:
# e.g:
es.index(index={index_name}, body={document}, refresh=True)
What does refresh do?
- Essentially ES performs a
WRITEoperation on a document, it is buffered into memory for better indexing performance. - These buffered changes are then periodically written to disk in a process called
refresh.
PUT /test/_doc/1?refresh=true|false|wait_for
{"test": "test"}
- Lucene writes to an immutable segment and is eventually flushed to disk.
-
The flush operation is not synchronized across nodes, so it is possible to get different results for a short time period for the same request as well.
- There are also some potential optimisations that I’ve looked into:
- Search slicing
- What this does is that ES will split the search into different slices and consume them independently.
- We can think of it as ES running the search in parallel on 2 different distinct portions of the indices and then combining them at the end
- By default the splitting is done first on the shards, then locally on each shard.
- The local splitting partitions the shard into contiguous ranges based on Lucene document IDs.
- But it seems like the number of slices is still better to be the same number as the number of shards
- https://stackoverflow.com/questions/43211387/what-does-elasticsearch-automatic-slicing-do
The ideal number of slices should be a multiple of the number of shards in the source index. For the best performance, you should pick the same number of slices as there are shards in your source index. For that reason, you might want to use automatic slicing instead of manual slicing, as ES will pick that number for you.
- However, I eventually found out that you can’t really perform
search slicingwithsearch afterbecause the entire premise ofsearch afteris providing the checkpoint to the next iteration to continue searching from. - It is difficult to do this together with
search slicingbecause you need to somehow manage/wrangle the checkpoint of the first slice operation and ensure that it does not overlap with the second slice’s search operations. - Because of this,we will keep getting duplicated results.
- Turning off merge when doing bulk indexing
- Source: https://thoughts.t37.net/designing-the-perfect-elasticsearch-cluster-the-almost-definitive-guide-e614eabc1a87
GET /_cat/thread_pool/search?v&h=host,name,active,rejected,completed
- Increase or disable refresh rate
- https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-update-settings.html
- Search slicing
Overall it was an interesting exercise deep diving (no pun intended hehe) into search after and how it works. Hopefully you might find this small post somewhat helpful when thinking about deep pagination in Elasticsearch.
References:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/point-in-time-api.html
- https://levelup.gitconnected.com/elastic-search-simplified-part-2-342a55a1a7c7