Optimizing slow queries in a rapidly growing Postgres Table - Part 2
This article continues from Optimizing slow queries in a rapidly growing Postgres Table - Part 1.
If you would like to understand the context behind the problem, do check it out!
D.7 Partitioning
- Partitioning refers to the breaking up of a table into smaller logical chunks
- Logical because it has no storage on its own as they appear to be
virtual
Declarative Partitioning The partitioned table itself is a “virtual” table having no storage of its own. Instead, the storage belongs to partitions, which are otherwise-ordinary tables associated with the partitioned table.
Each partition stores a subset of the data as defined by its *partition bounds*. All rows inserted into a partitioned table will be routed to the appropriate one of the partitions based on the values of the partition key column(s). Updating the partition key of a row will cause it to be moved into a different partition if it no longer satisfies the partition bounds of its original partition. Src: https://www.postgresql.org/docs/current/ddl-partitioning.html#DDL-PARTITIONING-DECLARATIVE - Logical because it has no storage on its own as they appear to be
- Good to read Major enhancements to Partitioning in PostgreSQL 11:
- Improvements to partitioning functionality, including:
- Add support for partitioning by a hash key
- Add support for
PRIMARY KEY,FOREIGN KEY, indexes, and triggers on partitioned tables - Allow creation of a “default” partition for storing data that does not match any of the remaining partitions
UPDATEstatements that change a partition key column now cause affected rows to be moved to the appropriate partitions- Improve
SELECTperformance through enhanced partition elimination strategies during query planning and execution
Source: https://www.postgresql.org/docs/11/release-11.html
Check out E.22.3.1.1 for more info on partitioning
- Improvements to partitioning functionality, including:
How does partitioning solve our problem for us?
• Query performance can be improved dramatically in certain situations, particularly when most of the heavily accessed rows of the table are in a single partition or a small number of partitions. Partitioning effectively substitutes for the upper tree levels of indexes, making it more likely that the heavily-used parts of the indexes fit in memory.
• When queries or updates access a large percentage of a single partition, performance can be improved by using a sequential scan of that partition instead of using an index, which would require random-access reads scattered across the whole table.
Src: https://www.postgresql.org/docs/current/ddl-partitioning.html#DDL-PARTITIONING-OVERVIEW
- These 2 points reflect very similarly to our query access pattern to
crm_contacttable - In our case, we query for upserted agent contacts based on
user_idfor internal sales members, everytime we need to fetch relevant information for a particular internal sales agent, we are dealing with a relatively big table of 1.3m rows,- During which operations, such as
hash joinsare applied on the entire inner and outer tables and the relevant indices might need to be scanned in their entirety, adding significant overhead to many queries, including in memory requirements, especially during counts without much filters.
- During which operations, such as
- Multiple sql queries on the same large table have potential to lock up the table, where as splitting up the contacts may help to improve concurrency of sql queries
- Having a partition for each of these internal sales team members also increases and makes it easier to collect more statistics for each of these
user_idpartitioned partition on a per table basis. - It makes it easier for us to manage data for internal sales users who are no longer with the firm
ANALYZEandVACUUMops are now performed on smaller partitions and the overhead required is much smaller- We can just drop/detach the partitioned table for that user, and we do not require any
VACUUMto get the space back (as opposed to something likeDELETE FROM .. WHERE…) - Source: https://www.adyen.com/knowledge-hub/introduction-to-table-partioning
Indexing vs Partitioning
-
Benefit for partitioning is that INSERT, UPDATEs and DELETE statements will run alot faster because non clustered index on the current partitioned tables will be much smaller
-
Partitioning method chosen:
- We decided to go with
Listpartitioning because:- The type of internal sales users are more or less predetermined and defined and they do not change often.
- We can identify them via our internal
user_id
- We can identify them via our internal
- Downside is that it does not offer control over partition sizes
- But we do not think it is an issue because our platform should have already ingested most, if not all of the agents who are registered with CEA
- Hence the
countof agent contacts per sales team member shouldn’t increase too drastically
- The type of internal sales users are more or less predetermined and defined and they do not change often.
- Why not
range- Conversely, the query pattern is heavily reliant on
user_idso there is no range to partition on.
- Conversely, the query pattern is heavily reliant on
- Why not
hash- Normally a modulo will be applied on the partition key (numeric key) and that determines the number and location of your partitions
- Also,
user_idis based on UUID so it is also difficult to use thehashstrategy to partition at the point in time when we implemented this -
Furthermore, the number of partitions is predetermined and it may be hard to change in the future as well:
Flexibility is also an issue. Once you choose the divisor for the modulo operation, changing it in the future becomes problematic. You might already have a lot of data in the existing partitions, and since you can only increase the value of the divisor , the new partitions will effectively be much smaller… as you can see, not a very flexible approach.
- We decided to go with
When should you do partitioning?
These benefits will normally be worthwhile only when a table would otherwise be very large. The exact point at which a table will benefit from partitioning depends on the application, although a rule of thumb is that the size of the table should exceed the physical memory of the database server.
- While this was the conventional wisdom, we found that list partitioning helped to solve our challenge.
- To recap, at the point in time our
crm_contactwas ~ 1GB while our memory in dev and prod was 3.75GB and 6.5GB respectively.- Ignoring the CPU configuration,
devis only 2.3GB/3.75GB (60%) of memory whileprodis using 6.4GB/7.5GB (85%)
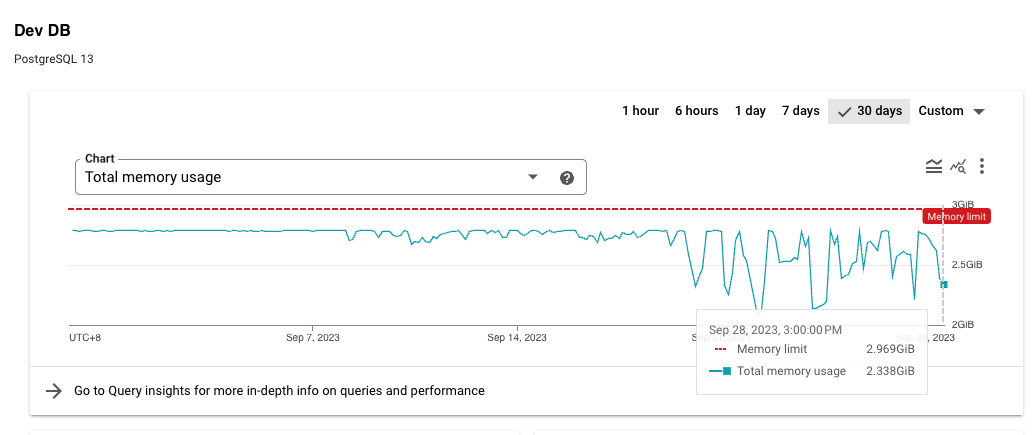
- Even though the memory pressure was much lower than in prod, we still found that the query was similarly slow
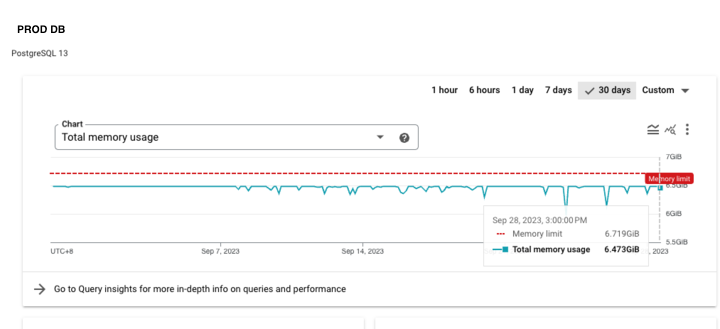
- Ignoring the CPU configuration,
Table Partitioning Process and Challenges
- General challenges faced when performing partitioning
crm_contact- An existing table cannot be simply
ALTER-ed to become a partitioned table
It is not possible to turn a regular table into a partitioned table or vice versa. However, it is possible to add an existing regular or partitioned table as a partition of a partitioned table, or remove a partition from a partitioned table turning it into a standalone table; this can simplify and speed up many maintenance processes.
See ALTER TABLE to learn more about the
ATTACH PARTITIONandDETACH PARTITIONsub-commands.- Hence a migration of data from the existing
crm_contactis required - Pitfalls included:
-
Not inserting in the existing
id(which isSERIALand generated by the db), hence the existing rows might have had differentids which could no be reconciled. - Remember to update the sequence of
crm_contact_seq_valcorrectly for the new table- This lead to alot of confusing conflicting entries on subsequent inserts because the
crm_contactid is set to beBIGSERIALwhich is incremented automatically.
- This lead to alot of confusing conflicting entries on subsequent inserts because the
- Primary key now needs to include partitioning key - creating a composite key
- In our case the primary key is now usually a composite key
- Not too much research was done on whether the order matters (because not enough time) and how it affects performance
- In our case the primary key is now usually a composite key
- Foreign key and Unique constraints will require the composite primary key to be included as well
- As some existing tables such as
crm_contactdid not haveuser_idfor most of the contacts, this usually results in the failure of the constraintuser_idand its originalidwhen referencing another table - Data patching of the
user_idwas required, based on the correspondingcrm’s cea_number was performed, else it is upserted asplaceholder - For tables such as
crmandcrm_messagesandcrm_group_contactwhich referencescrm_contact, this means that in order for the constraint to work, the correspondingid/contact_idanduser_idmust be found in both the inner and outer tables- However this was not true because
user_idwas not always populated in all of these places and some data patching was again required
- However this was not true because
- A special case was that initially when the constraint were to be applied, all the fields must be present in the table.
- E.g if we apply a constraint (contact_id, user_id) referenced to
crm_contactfromcrm_group_contact, all thecontact_idanduser_Id - But subsequently if part of these fields are null, e.g maybe a particular row has
contact_idbutnulluser_idthe constraint may not fail. -
This is because postgres does not enforce such constraint forcefully unless we apply
MATCH_FULLNormally, a referencing row need not satisfy the foreign key constraint if any of its referencing columns are null. If
MATCH FULLis added to the foreign key declaration, a referencing row escapes satisfying the constraint only if all its referencing columns are null (so a mix of null and non-null values is guaranteed to fail aMATCH FULLconstraint). If you don’t want referencing rows to be able to avoid satisfying the foreign key constraint, declare the referencing column(s) asNOT NULL. Src: https://www.postgresql.org/docs/current/ddl-constraints.html- But the performance impact might have been affected, so we did not further impose this, since the existing implementation had worked effectively beforehand anyway.
- E.g if we apply a constraint (contact_id, user_id) referenced to
- As some existing tables such as
- An existing table cannot be simply
Steps taken to partition crm_contact
Tables can only be partitioned at their creation, making it nontrivial to apply partitioning to a busy database. Src: https://docs.gitlab.com/ee/development/database/table_partitioning.html
- Live table partitioning with zero downtime can be challenging because
- tables can only be partitioned on their creation, means we need to perform the migration of the unpartitioned table to a partitioned one on a live system
- we usually require 0 downtime and minimize incoming request failures
- In our case it is not that crucial as there were not many live users, but in any case the entire process was over in less than a few minutes.
- There are many guides online that cover their experiences of performing partitioning live, but they are usually context specific and not always very 100% applicable.
- Nevertheless, it is the hope of this walkthrough to give some ideas and suggestions on how one may carry out partitioning on a live table.
Data migration strategies
- The general steps are as follows:
- Perform the entire operation in a transaction so that everything can be easily rolled back.
- Lock the existing
crm_contactinEXCLUSIVE MODEand rename it tocrm_contact_old- This is to prevent existing endpoints from writing to this table with new information
- The downside is of course that the queries will hang for the duration of this data migration, and might lead to a cascading effect.
- But for the scale of our app which has close to 0 real time users, this was not a significant problem
-
Creating the new partitioned table i.e:
CREATE TABLE IF NOT EXISTS crm_contact ( --...(schema is redacted) ) PARTITION BY LIST (user_id); -- this is the important part - Replicate the indices that were on
crm_contact_oldoncrm_contact- They are automatically propagated down to the children partitioned tables, so we don’t have to create indexes manually for each of the partitioned child tables
- Check out how local partitioned indexes work in PostgreSQL 11
- They are automatically propagated down to the children partitioned tables, so we don’t have to create indexes manually for each of the partitioned child tables
- Ingest the data from
crm_contact_oldtocrm_contact- There are 2 alternatives either:
- do
\copy-
This command is almost always faster than
INSERTeven ifPREPAREis used and multiple insertions are batched into a single transaction
-
INSERT INTO- However, the main problem with using
\copywas thatuser_idwas not available incrm_contact_old. - Since
user_idis required as part of the new composite primary key, so we had to opt for the next option which isINSERT INTO, which allowed us to specify aplaceholdervalue foruser_idto first fulfill the composite key requirement.
- However, the main problem with using
- do
- There are 2 alternatives either:
- Setting the new
crm_contact_id_seq1to be of parity withcrm_contact_id_seq’s last value, so that new inserts create the right incremental id. This is achieved by doing:
SELECT setval('crm_contact_id_seq1', (SELECT last_value FROM crm_contact_id_seq));- Lastly, we recognized that while the pre-partitioned
crm_contacthas been renamed tocrm_contact_old, the constraints in the other surrounding tables are still referencing the constraints incrm_contact_old.- This means we need to drop these constraints and point them to the new partitioned
crm_contacttable. - Most of these were appendable to the tables i.e
crmandcrm_group_contact, however there were abit more complications with the other tables such ascrm_messageswhere there were certain data inconsistencies. - The data patching and clean up process involved the following:
- Deleted inconsistent data that were non instrumental.
crm_messagesrows essentially only serve as a historical timeline of the messages sent out for building a timeline in the future. We assessed that most of these data inconsistencies came from initial testing users in production and were safe to be deleted
- Updated
crmandcrm_contactwithuser_idsfrom existing production data from user service
For more information, the script can be referred here.
- Deleted inconsistent data that were non instrumental.
- This means we need to drop these constraints and point them to the new partitioned
Safeguards during Migration Process
- We naturally performed a
pg_dumpof the entire LMS database to prepare a version for rollback in case something went awry.
Post Partitioning Checks
- We recognized that most of these actions involved SQL scripts. So we used corresponding SQL scripts were to test for data integrity as well.
- Ensuring that
crm_contactandcrm_contact_oldhas the same data (except for user_id)- The following script uses
except(set difference operator). It is a set operator in SQL that returns the distinct rows that are present in the result set of the first query, but not in the result set of the second query. - So this script tries to retrieve all the data that is present in:
crm_contactbut not incrm_contact_old,crm_contactbut not incrm_contact
Source: https://www.scaler.com/topics/except-in-sql/
- The actual script is redacted but the concept is similar to the one in this stackoverflow answer
- The following script uses
Ensuring that crm_contact sequence is equal to crm_contact_old
SELECT
CASE
WHEN (
(SELECT last_value FROM crm_contact_id_seq1)
=
(SELECT last_value FROM crm_contact_id_seq)
)
THEN TRUE
ELSE FALSE
END AS is_greater
N.B Only INSERT operations will increment the serial number, and not when you UPDATE or DELETE Hence, setting = should be stricter and sufficient.
Ensure that the dropped and re-added constraints exists
We can check from information_schema.table_constraints on whether all the constraints exist.
SELECT CASE WHEN COUNT(*) = 4 THEN true ELSE false END AS all_constraint_exists
FROM information_schema.table_constraints
WHERE constraint_name IN (
'crm_messages_contact_id_fkey',
'crm_group_contact_contact_id_fkey',
'crm_lead_contact_id_fkey',
'crm_id_user_id_unique'
) AND table_name IN (
'crm_messages',
'crm_group_contact',
'crm'
);
crm_messages_lead_id_fkey,is dropped because there exists some conflicting data inprodwhich was not resolved at the moment.
Post Partitioning EXPLAIN ANALYZE results
— Chosen select projections are very performant all round, without any filtering on crm_agent_info at < 2ms.
- Actual query is redacted but here are the results:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Limit (cost=27.81..89.34 rows=20 width=488) (actual time=0.879..1.789 rows=20 loops=1) -> Nested Loop Left Join (cost=27.81..111976.05 rows=36388 width=488) (actual time=0.877..1.785 rows=20 loops=1) Join Filter: (contact.id = groups.contact_id) Rows Removed by Join Filter: 3020 -> Nested Loop (cost=0.83..38623.13 rows=36388 width=448) (actual time=0.076..0.497 rows=20 loops=1) -> Index Scan using crm_contact_part_user_xx_yy_contact_display_name_idx on crm_contact_part_user_xx_yy contact (cost=0.41..6567.43 rows=52294 width=193) (actual time=0.015..0.091 rows=36 loops=1) Filter: (is_active AND (user_id = 'xx_yy'::text)) -> Index Scan using crm_agent_info_pkey on crm_agent_info agent_info (cost=0.41..0.61 rows=1 width=278) (actual time=0.010..0.010 rows=1 loops=36) Index Cond: (id = contact.agent_info_id) Filter: (agent_status = 'active'::text) Rows Removed by Filter: 0 -> Materialize (cost=26.98..30.70 rows=135 width=48) (actual time=0.034..0.046 rows=151 loops=20) -> Subquery Scan on groups (cost=26.98..30.02 rows=135 width=48) (actual time=0.669..0.738 rows=151 loops=1) -> HashAggregate (cost=26.98..28.67 rows=135 width=48) (actual time=0.669..0.719 rows=151 loops=1) Group Key: gc.contact_id Batches: 1 Memory Usage: 96kB -> Hash Join (cost=16.41..25.29 rows=169 width=31) (actual time=0.182..0.279 rows=177 loops=1) Hash Cond: (gc.group_id = g.id) -> Seq Scan on crm_group_contact gc (cost=0.00..8.43 rows=174 width=31) (actual time=0.019..0.063 rows=183 loops=1) Filter: (status = 'active'::status) Rows Removed by Filter: 17 -> Hash (cost=11.78..11.78 rows=371 width=23) (actual time=0.153..0.154 rows=376 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 29kB -> Seq Scan on crm_group g (cost=0.00..11.78 rows=371 width=23) (actual time=0.006..0.090 rows=376 loops=1) Filter: (status = 'active'::status) Rows Removed by Filter: 9 Planning Time: 0.970 ms Execution Time: 1.953 ms - Count query on
crm_contactbyuser_idwith active status and contact is also much more performant than the initial ~750ms execution time, to 60ms, which is a 92% speed up or ~ 12.5 times.
explain analyze (SELECT
COUNT(*)
FROM
crm_contact contact
LEFT JOIN
crm_agent_info agent_info
ON
agent_info_id = agent_info.id
WHERE user_id = 'xx_yy' AND contact.is_active = True
AND agent_status = 'active');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=4711.30..4711.31 rows=1 width=8) (actual time=59.675..59.678 rows=1 loops=1)
-> Hash Join (cost=1513.34..4620.07 rows=36489 width=0) (actual time=22.273..57.348 rows=36340 loops=1)
Hash Cond: (contact.agent_info_id = agent_info.id)
-> Seq Scan on crm_contact_part_user_xx_yy contact (cost=0.00..2969.49 rows=52279 width=23) (actual time=0.016..15.872 rows=52294 loops=1)
Filter: (is_active AND (user_id = xx_yy::text))
-> Hash (cost=1057.11..1057.11 rows=36499 width=23) (actual time=22.011..22.012 rows=36340 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2464kB
-> Index Only Scan using ix_crm_agent_info_active_listing_types on crm_agent_info agent_info (cost=0.41..1057.11 rows=36499 width=23) (actual time=0.056..13.305 rows=36340 loops=1)
Heap Fetches: 53
Planning Time: 0.813 ms
Execution Time: 60.023 ms
(11 rows)
- Notably we can see that the hash join cost went down significantly as compared to the test data in
devpre partitioning:
Dev data partitioning
cost=6022.15..47615.08
- N.B, initially because the query planner was still using outdated statistics/ old plans, the latency was around ~150ms.
- We had to do
VACUUM ANALYZEso that the query planner is updated with the relevant stats
explain analyze (SELECT
COUNT(*)
FROM
crm_contact contact
LEFT JOIN
crm_agent_info agent_info
ON
agent_info_id = agent_info.id
WHERE user_id = 'xx_yy' AND contact.is_active = True
AND agent_status = 'active');
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=5109.45..5109.46 rows=1 width=8) (actual time=157.529..157.533 rows=1 loops=1)
-> Hash Join (cost=3068.53..5018.48 rows=36388 width=0) (actual time=78.497..149.629 rows=36340 loops=1)
Hash Cond: (contact.agent_info_id = agent_info.id)
-> Seq Scan on crm_contact_part_user_xx_yy contact (cost=0.00..1812.68 rows=52294 width=23) (actual time=0.009..32.262 rows=52294 loops=1)
Filter: (is_active AND (user_id = 'xx_yy'::text))
-> Hash (cost=2613.68..2613.68 rows=36388 width=23) (actual time=78.397..78.398 rows=36340 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2464kB
-> Seq Scan on crm_agent_info agent_info (cost=0.00..2613.68 rows=36388 width=23) (actual time=0.009..43.770 rows=36340 loops=1)
Filter: (agent_status = 'active'::text)
Rows Removed by Filter: 15954
Planning Time: 0.380 ms
Execution Time: 157.609 ms
(12 rows)
Conclusion
- In summary, the right solution turned out to be using partitioning to segment the data into smaller searchable chunks to optimise the DB queries.
- The overall process as seen can be tedious, and could be even more so if we have to allow for concurrent write operations to the old and new tables to prevent data loss.
- We achieved positive results where the query speed post partitioning actually increased by up to 92%!
Without a doubt I was a very happy engineer that day. Thanks for reading!
####Other sources and references:
- https://www.macrometa.com/distributed-data/database-indexing-and-partitioning
- https://engineering.workable.com/postgres-live-partitioning-of-existing-tables-15a99c16b291